Several years ago I wrote a few thoughts on Grove words. One of the points I made is that some Grove words are likely to be valid. I specifically made this argument:
Yet 31% of words with the gallows removed have no occurrences, which presses for an explanation. There may be two reasons for this. One is that such words are genuinely unique. They properly do not begin with a gallows character but as their only occurrence is at the beginning of a paragraph their form as a Grove Word is the only one known.
The other reason is that some Grove Words properly begin with a gallows glyph. Whatever process adds a gallows to the beginning of Grove Words does not happen if that word already begins with one. It may be that removing the gallows from such a word does result in a more common word, even if both are still valid.
Reviewing my words, the second paragraph calls an even simpler explanation to mind: over 2,000 words in the Voynich text begin with [k] or [t]; none begin with two gallows.
If true, we must ask how the reader knew which gallows were valid and which were added? In our current state of knowledge we can identify some invalid words through their structure. Is there an easier way which we’ve missed?
18 August 2021, Edit: I realise that plenty of Grove words do contain two gallows, just not adjacently. Nor are there any words which start [pr] or [pl], which we would expect to occur a few times. There are, however, 64 words which begin [pol] and 17 which begin [por], of which 52 and 15, respectively, are paragraph initial. Paragraph initial words which begin [pok], [pot], and [pyk] also exist, though in tiny numbers.
Thinking back to the division between ‘strong’ and ‘weak’ glyphs, it feels almost that, even though the initial gallows is an addition, it won’t sit adjacent to other ‘strong’ glyphs and other glyphs need to be inserted. I’m jumping several steps ahead, I know, but it would suggest that the initial gallows in Grove words is not purely decorative but retains some of its original features which means that [pk], [pt], [pr], and [pl] are unacceptable.
(Though it’s worth noting that [pd] is acceptable – and in any position, not only initially. In fact, [pd] is as common as [td] and [kd] combined.)
A little while ago I made a post about benches [ch] and [sh] at the start of a line. In the post I attempted to “restore” words with initial benches by removing preceding glyphs. The attempt wasn’t a great success and I could not find the solid answer that I wanted.
I’ve begun approaching the problem of line patterns more systematically, which I hope will provide more answers over time. One part of that approach is to work with parts of the text with a single scribe and topic. So everything in the following post will apply only to text written by Hand 1 on herbal pages.
Problem
Words with initial benches are less common in that first position than in the rest of the line. Yet the total number of word containing benches remains broadly unchanged. The table below provides the relative frequency of words containing [ch] and words with initial [ch].
1
2
3
4
5
Containing [ch]
0.41
0.42
0.39
0.37
0.32
Initial [ch*]
0.05
0.30
0.25
0.22
0.19
I have limited the examples to [ch] as the pattern is stronger and clearer than for [sh]. (The frequency declines to the right due to another line pattern which reduces frequency in the last line position.)
The total number of words with initial [ch] which are missing from the first position is around 250-300 words, but it is impossible to estimate precisely.
What remains
In the earlier post I looked at words which might contain the benches which had been “moved” to the middle of a word. It appears that the glyphs [y], [d], [o], [s], [t], and [p] all have a higher frequency before [ch] in the first line position. But I don’t want to discuss that yet.
The more interesting question concerns the words with initial [ch] which remain in the first line position. If we look more closely at them we can see a striking pattern. (The table below shows the number of occurrences for words beginning with the specified strings, including those for which the string constitutes the complete word.)
1
2
3
4
5
[cho*]
59
213
168
141
82
[chy*]
1
22
26
14
18
[cha*]
0
17
22
12
11
[che*]
0
85
56
53
38
[chk*]
2
9
11
8
9
[cht*]
0
8
0
3
4
[chckh*]
0
4
12
2
2
[chcth*]
0
7
2
6
11
The numbers are very clear: almost the only words with an initial [ch] in the first line position are those beginning [cho*]. Words beginning [che*], for which we might expect to see ten occurrences even at the reduced rate of initial [ch], simply don’t occur.
We can go one step further with this line of investigation. Words beginning [cho*] are themselves less common than expected, even if they do occur. Is there a pattern to what words with initial [cho*] remain?
(As before, the table below shows the number of occurrences for words beginning with the specified strings, including those for which the string constitutes the complete word.)
1
2
3
4
5
[cho] (Complete word)
2
16
13
8
3
[chok*]
17
22
13
19
10
[chot*]
11
10
18
12
6
[chod*]
5
18
11
13
7
[chos*]
0
4
5
1
2
[chor*]
7
60
34
21
13
[chol*}
10
65
55
53
24
We can see that while words beginning [chok*] and [chot*] remain in line with the expected numbers, all other words are less common than expected. Words beginning [chor*] and [chol*] are particularly less common (most of these, in all positions are the complete words [chor] and [chol]).
(As a side note, words with final [l] are less common in the first line position, but words with final [r] are more common, so the numbers about about [chor] and [chol] don’t clearly fit into a wider pattern.)
Thoughts
The process which decreases the number of words with initial [ch] in the first line position is not random. It does not indiscriminately reduce the numbers of such words so that they are all less common. It strongly affects some words but leaves others untouched.
Words beginning [che*] and [cha*] are all gone. The words [chor], [chol], [chy] and [cho] are significantly reduced. But words beginning [chot*] and [chok*] are unaffected.
Of those words beginning [chot*] and [chok*], only three have more than one token in the first line position, the rest being unique to this position. The process is not leaving specific words untouched, but words with specific features. The process is not dumb, and it does not work strictly on the initial glyph alone.
For those words with initial [ch] which appear to gain an extraneous glyph to begin [dch], [ych], [och], [sch], [tch], and [pch] in the first line position, it remains unknown why one glyph is chosen over another. It has been proposed, quite reasonably, that there is an influence from the last word of the line before. Yet the information in this post suggests that the process is aware of, and responsive to, the features in the word it affects. Words beginning [dch] may have some feature in common with one another which those beginning [ych] or [och] do not.
The last two posts on this site have been very similar. Not only have the investigations sought to prove similar things using similar methods, but the result of both was failure. Neither managed to prove the hypothesis I sought to test.
Yet I’m going to do it again. Many times. Even though I know that hanging on to disproven ideas makes me a crank.
Let me explain.
Line Patterns
Prescott Currier was the first to mention that the distribution of glyphs in a line is not flat. Some glyphs seem more or less likely to appear in words at the beginning or end of a line. In Currier’s words, “the occurrence of certain symbols is governed by the position of a ‘word’ in a line.”
It is highly unusual that a text responds to a page in this way. Our experience with writing and reading tells us that we compose a text independent of the page upon which it might be presented. An acrostic is the main exception which comes to mind, with its message hidden in the first or last letters of a line. Poetry might be considered a further example, with layout often governed by meter and rhyme.
Currier’s description of the phenomenon was that that, somehow the “line is a functional entity.” He conceded that he didn’t know what the function might be or what process would create the lines as we see them. Sadly the records of Currier’s work are quite sparse given his influence, so his further thinking on this matter is unknown.
Improved access to imagery, multiple transcriptions, and the ubiquity of computers have allowed us to more thoroughly explore how glyphs are distributed in a line. We know that distribution of glyphs is not flat in any major part of the text, that many glyphs demonstrate this kind of distribution, and that the phenomenon exists for the second position in a line, not only the first and last. The picture is more complex but still essentially the same as that painted by Currier.
The only point I wish to make is that Currier’s idea of the line as a “functional entity” is unproven. It could be correct, and given time and evidence it may be proven so, but the description is too strong for the evidence we have. The observations are correct and the judgement that the distributions are unusual is also correct. But what the distributions mean and how they were created is unknown. The words “functional entity” describe an hypothesis, not the observations.
I will refer to them by they blander, but safer and neutral, “line patterns”.
Describing the patterns
For anybody who hasn’t studied the text of the Voynich manuscript in any depth, the foregoing discussion may seem to float above the ground. No examples from the text were offered to illustrate line patterns. A few would help to show what Currier, and subsequent researchers, have seen.
The “Stars” section of the manuscript, which fills Quire 20, has almost 1,000 words beginning with the glyph [a]. Only 3 of them occur at the start of a line, though we might expect around 100.
Part of the Herbal section has just over 300 words ending with the glyph [m]. Over half of them occur at the end of a line.
Words beginning with [ch] or [sh] are around 70% more frequent than expect in the second position of a line.
These kinds of patterns, sometimes of the same strength but often weaker, can be found for many glyphs. Some glyphs may be more frequent at the start and end of a line. Others may be more or less frequent depending on where they appear in a word: words with a final [l] are less frequent at the end of a line, but words containing [l] occur at the same frequency in that line position. Finally, the line patterns may differ by scribe and section.
In my two previous posts I’ve tried to show line patterns by providing the number of occurrences for each word, glyph, or feature, in different line positions. I have numbered the line positions using positive and negative numbers: 1 to 5 describe distance from the start of a line (1 being closest) and -5 to -1 describe distance from the end of a line (-1 being the closest). Although I’ve seen no line patterns which extend beyond the second position from the start or end of a line, the further out positions are provided to demonstrate what the normal distribution looks line.
(I realise that raw counts of how many times a word occurs may be misleading in some circumstances. For many lines position 5 and -5 may overlap. For a single word line 1 and -1 are the same position. And in these cases the furthest distant positions may show lower counts for a word’s occurrence simply because, in some cases, a word doesn’t exist in that position. The counts for each position should be weighted or provided as a ratio of total words in that position.)
Is the lack of flatness a problem?
Nothing in nature is random. Everywhere there are processes which create the patterns we see around us. When we read a text in English we do not expect to see as many occurrences of the word “Neorxnawang” (a real word!) as the words “and” or “the”. Nor as many occurrences of the letter “x” as of “e” or “t”.
Yet the distribution of glyphs in a line of Voynich text is unusual. A process must have created it, as we can observe it, and the text is too long for the statistics we have to be missampled or skewed by chance. But there are no processes in our experience which easily explain the distribution that we see. So how to we reliably learn about this unknown process?
The bulk of the Voynich text, away from the start and end of lines, was also created by a process. That process is likewise unknown, though we have a larger sample from which to learn. The larger amount might also tempt us to assume that the middle positions of the line are ‘normal’ for Voynich and the line starts and ends ‘abnormal’. This assumption is useful to move forward with research, though it is important not to hold onto the assumption beyond its usefulness.
So we can rephrase the question of whether the lack of flatness is a problem and form a new question suitable for research: how did the process which created the starts and ends of lines differ from the process which created the rest of the text? The research then is looking for a relative difference, not an absolute. We can make observations which set out the statistical differences, and that task has been done in part by several researchers, but this does not speak to the difference in process.
To get closer to the difference in process we must know what one process (which created the bulk of the text) would have created instead. What would the starts and ends of lines look like were they created with the same process as the rest of the text? How does the output of one process translate into the other? If we say that some sections lack words with initial [a] at the start of a line, what do they have instead?
Here I must open-handedly admit that the results of such investigations may be totally negative if the starts and ends of lines are fundamentally different. They may have different content, be unconnected with the rest of the lines, or even be empty padding. It is impossible to know. But without looking we have no chance of finding a positive answer, if it exists.
The perfect opportunity
This research proposal is what I want to called ‘line position mapping’. The name is not intended to excite or arouse curiosity. It only states what the investigations will seek to do and their place of focus in the text. The meaning of line position should be obvious from the discussion above. But the choice of the word ‘mapping’ is deliberate.
Another discovery of Prescott Currier was that sections of the text are statistically distinct. He referred to them as different languages or dialects, and labelled them A and B. This division is well-known to all but the most casual researcher of the Voynich manuscript.
Several researchers have sought to reconcile the two languages by finding correspondences between them. Language A may have many occurrences of certain glyphs or words which are much less frequent in language B. But language B may have its own most frequent glyph and words. So researchers have suggested, in various ways, how something in A matches or maps to another thing in B.
The problem they face is that language A and language B are used by different scribes and in different sections. We don’t know how much of the language difference is dependent on the scribe, on the content, or on some other variable. We cannot hold all the variables involved fixed enough to provide solid results. Any suggestion of a correspondence may be due to other reasons.
Line patterns and line position mapping provide an opportunity which sidesteps many of these problems. As line patterns occur within a line, we know that all the words of that line were written by the same scribe on the same topic. The difference – whatever it might be – must be due to the process of composition (or encoding) and not the individual or the topic.
Any result of these investigations, however partial, are much more solid than might be gained from attempting to map language A to language B.
What will we gain?
It is usually impossible to know exactly what knowledge a piece of research will deliver before we have the results. Even if we have a well-formed question to answer positively or negatively, the impact of the results on future research could be unforeseen.
I hope that two things will result from success in line position mapping. The first is that we should be able to make the text more regular. Words and phrase which may have previously lay hidden across a linebreak due to the influence of a line pattern, will suddenly become clear. The text may be more amenable to research on the relationships between words and phrase structure.
The second is that we will be able to draw relationships between glyphs and bigrams. In my previous post I sought to understand if bench gallows could be “unpacked” by looking at the statistics of words at the start of lines, where bench gallows don’t occur. The result was negative and I found nothing. But it was a possibility.
Another real possibility is explaining the nature of [m], which adheres to strong line pattern. Or maybe elucidating the difference between [ch] and [sh] which share similar, but not exactly the same, line patterns. There is the potential to learn more about any glyph which has a line pattern. Even understanding just one line pattern will teach us something we didn’t know before.
Which is why I’ve decided to become a crank when it comes to line patterns.
Many ideas in this post have been stated before elsewhere. I thought I would bring them together to make a complete argument for the importance of this area of research. I encourage other researchers to look into line patterns and undertake their own investigations into line position mapping.
This post is very long. A summary is provided at the bottom. The outcome is that I was unable to find an answer.
Bench gallows [ckh, cth, cfh, cph] appear to be combinations of a gallows [k, t, f, p] and a bench [ch]. They also seem to have links with both benches and gallows. The hypothesis that they are a combination of the two is a reasonable suggestion.
There is a further hypothesis that a bench gallows can be “unpacked”. These glyphs contains two features, and bench and a gallows, which can be separated and replaced by other glyphs with the same value. So [ckh] might be the same as [chk] or [kch]. A bench gallows is only an alternative way of writing other glyphs.
To investigate this hypothesis we will look at the text written by Hand 1. Hand 1 uses bench gallows more often than other hands. They also use them in all positions, including word-initial which is rare in other hands. Because [cfh] and [cph] are relatively uncommon through the text and may give unreliable results, we’ll concentrate on [ckh] and [cth].
Bench gallows in hand 1
Hand 1 wrote approximately 11,000 words of text. The glyphs [ckh] and [cth] occurs in 311 and 555, words respectively, or approximately 2.8% and 5% of words. Only three words contain two occurrences of either [ckh] or [cth], and only eight words have the bench gallows word-final. About 45% of [ckh] and 72% of [cth] are word-initial.
For a reason which we’ll discuss in a moment, this article will look at those words with an initial bench gallows. The most common words with initial [ckh] and [cth] in Hand 1 text are:
cthy
93
ckhy
27
cthol
52
ckhey
24
cthor
40
ckhol
18
cthey
37
ckheey
8
ctho
19
ckhor
7
cthody
14
ckheody
5
cthar
12
ckhody
4
cthaiin
12
ckheol
4
ctheey
11
ckhos
3
ctheol
9
ckham
3
cthal
6
ckhaiin
3
cthom
5
ckho
2
ctheody
5
ckheos
2
ctheor
4
ckheo
2
cthain
4
ckhal
2
The two lists are broadly similar, though with different orders and significantly different counts due to [ckh] being less common in this position. The main difference is that two [ckh] words end in [s]. Counterparts with [cth] do occur, but with lower token counts.
The main reason for choosing to look at word-initial bench gallows is the pattern they display depending on line position. Below are the counts of words with initial bench gallows in the first five positions in a line:
Line position
1
2
3
4
5
[ckh*]
0
40
23
23
18
[cth*]
3
67
69
68
51
In both cases few to no words occur in the first position of a line. The subsequent positions show that the number should be several dozens, assuming that distribution were smooth.
This present us with the opportunity for an investigation to discover more about the nature of bench gallows. The question is where the words with initial bench gallows went, and what we can learn as a result. Following will be a series of statements potentially explaining the absence of bench gallows in this position, with a discussion about their plausibility.
Line distributions aren’t flat.
The idea that the distribution of words in a line should be flat is an assumption. We have known for a long time, since at least the work of Prescott Currier in the 1970s, that line patterns exist for words and glyphs. Whether they should be flat is not something researchers have been able to establish.
But simply restating the observation that line distributions aren’t flat doesn’t progress the problem. We can acknowledge that the line distributions are a feature and still seek to explain them. Any explanation would take the area of explanation as the difference between flatness and not-flatness, just as irregularities are explained in terms of how they differ from the regular. Assuming flatness, or regularity, is a technique to spur investigation, not an attempt to ignore the text as it is.
Acknowledging the line distribution then choosing not to seek an explanation is the opposite of research. It ignores evidence of the processes which created the text, a point at which they changed, or overlaid, and resulted in an irregularity. Progress on understanding the Voynich manuscript will only be made if the text is not accepted as an inscrutable whole but instead considered a complex outcome from many smaller interlocking processes.
The words were simply moved elsewhere.
The possibility that words with initial bench gallows were simply moved away from the first position in a line seems vaguely plausible. We don’t know what the words are (“word” itself is an assumption used for ease) or why they appear in a sequence. It is easy to assume that they are sequential, as in language, and therefore unmovable.
Even if the text is a written language words could still be flexible in their position. Languages allow for a certain amount of flexibility in how a sentence is phrased. The statistics for [ckh] in the second line position show a larger number than subsequent positions, so could they have been moved there?
The statistics for words with initial [cth] are relatively flat in position 2-5, so there is little chance the words from the first position are to be found there. The wider point about flexibility is reasonable except that line distribution affects many glyphs and words. Some are more common in the first position, others more or less common in the last position, at the end of a line. To create all these patterns would mean that almost every line experiences some amount of reordering to achieve them. At what point does a text become unreadable?
Different words were chosen.
Similar to the statement above, a dedicated author in English can avoid the letter “e”, so why not words containing [ckh]? All languages have some degree of synonymy within their vocabulary/lexicon/wordhoard, so avoiding certain words is very possible.
The arguments against this statement are much the same as above, though with further problems. It is unlikely that every word will have a synonym yet there are no words with initial [ckh] in the first position.
The words were deleted without replacement.
This statement proposes a text which is literally missing words every single line. Information and meaning would undoubtedly be lost. It is hardly credible that such a process created the line patterns which we observe.
The bench gallows were removed from the words.
As above, removing the whole glyph could result in a serious loss of information from the text. But if the rest of the word remained then the lost information could be supplied by the reader. This statement can be tested with statistics.
We know the most common words with initial [ckh] and [cth]. Removing the initial bench gallows supplies a list which can be checked against actual occurrences, as in the table below:
Line Position
1
2
3
4
5
[y]
16
16
18
8
8
[ol]
13
18
14
11
9
[or]
17
15
13
8
6
[ey]
0
1
0
0
0
[o]
13
7
8
9
5
[eey]
0
0
1
1
0
[ody]
0
0
1
3
1
[eody]
0
0
0
0
0
[ar]
0
5
1
6
2
[aiin]
0
8
7
4
10
Only [o] shows an increased occurrence in the first position of a line. Yet for the hypothesis to be correct all such words would need to show a similar increase. We can say that the statement of bench gallows being removed from words in this position is almost certainly wrong.
Initial bench gallows is moved to an internal position.
The absence of initial bench gallows in the first position of a line could be due to the bench gallows moving position within a word. This could be the glyph moving in relation to others, or through additional glyphs being added before an initial bench gallows. Either way, this too should be easy to test with statistics.
Below is a table showing the number of words with non-initial bench gallows in different line positions.
Line Position
1
2
3
4
5
Non-initial [ckh]
19
25
39
22
20
Non-initial [cth]
22
28
22
19
25
The statistics show no increase in occurrences in the first line position, which would be expected if words with initial bench gallows had been altered in this position.
The gallows feature has been removed.
As bench gallows seem to be composed of two features – gallows and bench – it could be suggested that one feature is removed in the first line position to account for their lack of presence there. A bench gallows would become an ordinary bench. So the word [ckhy] becomes [chy], and so on.
The table below shows the line position statistics for the most common words with an initial bench gallows if the gallows were removed.
Line Position
1
2
3
4
5
[chy]
1
19
22
13
15
[chol]
12
67
54
50
21
[chor]
10
56
36
16
11
[chey]
0
18
20
14
8
[cheey]
0
9
6
4
1
The distribution statistics for words with initial [ch] do not suggest that bench gallows have been replaced with [ch] in the first position. All of the words are much less common in first position, as all words with initial [ch] are. In some cases – [chy], [chey], and [cheey] – the numbers are so low that there is no way to argue that additional words could have been added. Yet, for the hypothesis to be true, all such words should show an increase to accommodate the alternate words which previously had an initial bench gallows.
The bench feature has been removed.
As above, the bench feature could be removed to leave a gallows. So the word [ckhy] would become [ky], and so on.
The table below shows the line position statistics for the most common words with an initial bench gallows if the bench were removed.
Line Position
1
2
3
4
5
[ky]
0
1
5
1
4
[ty]
0
0
0
3
2
[kol]
2
3
6
4
3
[tol]
10
1
1
1
0
[kor]
2
2
4
3
1
[tor]
5
1
1
1
0
[key]
0
0
4
0
1
[tey]
0
0
0
1
0
[keey]
0
4
1
2
3
[teey]
0
0
2
1
1
The word [tol] shows exactly the kind of increase expected if [cthol] had become [tol]: an increase in the first position which is clearly above the normal distribution. [Tor] could be argued as having the same pattern, but we expect to see all words have this pattern, not only two. Words with initial [to*] are more common in the first position, with 50 occurrences against a normal 4-5, though that could be caused by any number of line patterns which affect the distribution of words.
An interesting result, but not the outcome we’re looking for.
Bench gallows are unpacked into a bench followed by a gallows.
In this case the bench gallows [ckh] would become [chk]. So the word [ckhy] becomes [chky].
Another table is unnecessary in this case: the words mostly don’t exist in any position. The words are valid, but so uncommon throughout the text. We would expect maybe 10 occurrences of [chty] in the first line position, but only 7 occur in the whole of Hand 1.
The hypothesis is defintiely wrong.
Bench gallows are unpacked into a gallows followed by a bench.
In this case the bench gallows [ckh] would become [kch]. So the word [ckhy] become [kchy].
The table below shows the distribution of words with initial bench gallows altered in this way.
Line Position
1
2
3
4
5
[kchy]
0
7
5
6
3
[tchy]
1
2
2
6
5
[kchol]
2
6
7
3
1
[tchol]
2
1
2
3
2
[kchor]
6
5
1
2
2
[tchor]
10
3
1
2
0
[kchey]
2
0
2
3
1
[tchey]
0
3
1
0
2
[kcheey]
0
1
1
0
0
[tcheey]
0
1
1
2
0
The word [tchor] alone appears to show the kind of distribution we might expect. The others definitely do not. And, as above, either all the word show signs on the correct distribution or the hypothesis should be considered false.
For the sake of completeness I also ran the statistics for replacing a bench gallows with a gallows followed by [sh] rather than [ch]. So [ckh] would become [ksh]. While [tshor] and [tshol] show promising signs of the correct distribution, not other words did.
Some more complex change happened.
This statement is really a final catchall possibility. A free pass for me to look for some possible set of words which could, be regular alterations, represent word initial bench gallows in the first position of a line. The only criteria are that the transformations must be regularly applied to all such words and they must all have the correct line distributions: common in the first position and less common (or rare) thereafter.
Where to look for these missing words, if we can look anywhere? Hand 1 contains 140 and 398 word with word initial [ckh] or [cth]. Line lengths vary but (accounting for labels which have a line length of 1) the typical line might have 8 words. So the numbers of words with initial bench gallows should be about 1/7 higher: 20 [ckh] and 57 [cth], or 60+ in total if we allow a margin of variability.
Perhaps the most promising are words with initial [o] or [qo]. Both are more common in the first line position, and much of the difference in both cases is due to words containing gallows, as the table below shows.
Line position
1
2
3
4
5
[ok*]
103
58
81
59
58
[ot*]
95
42
43
55
51
[qok*]
87
39
73
70
46
[qot*]
80
29
32
31
32
In general, these are the kinds of distributions we would want to see. There is plenty of “excess” words in the first position where bench gallows could exist. Although these words rarely contain bench gallows, they could be combined with another alteration. The most likely is having the bench gallows unpack to a gallows followed by a bench. So in these cases the word [ckhy] would become either [okchy] or [qokchy].
The next table will show the distributions of words with initial bench gallows altered in the way of [ckhy] to [okchy].
Line position
1
2
3
4
5
[okchy]
3
1
3
1
2
[otchy]
4
0
5
3
0
[okchol]
1
1
2
0
2
[otchol]
10
2
0
4
4
[okchor]
3
3
3
1
0
[otchor]
6
2
2
0
4
[okchey]
3
1
3
0
2
[otchey]
2
2
3
2
0
[okcheey]
1
0
0
0
0
[otcheey]
0
0
0
1
0
The distributions of most these words show no sign of additional occurrences in the first position. Only [otchol] shows a marked increase. This cannot be the correct hypothesis.
The table below shows the distributions of words with initial bench gallows altered in the way of [ckhy] to [qokchy].
Line position
1
2
3
4
5
[qokchy]
12
7
8
3
4
[qotchy]
14
9
2
9
4
[qokchol]
2
3
3
2
1
[qotchol]
2
1
2
2
2
[qokchor]
5
2
0
1
0
[qotchor]
9
0
1
1
0
[qokchey]
1
0
0
2
0
[qotchey]
2
0
2
2
1
[qokcheey]
0
1
0
0
0
[qotcheey]
1
0
0
0
0
Although the results are marginally better, with several words showing increased occurrences in the first position, none are very strong and all words should show a consistent pattern.
Summary
The nature of bench gallows is an unresolved question. Specifically whether or how they can be “unpacked” into constituent parts.
The start of lines in the Hand 1 text provides an opportunity to investigate this question, as word initial bench gallows occur far less in this position than they should. By finding what replaces such words we should gain an insight into the nature of bench gallows.
Multiple sets of words were proposed by regularly altering those words with initial bench gallows. However, there is no set of words which have a matching distribution for the missing words in the first line position.
This environment still has the potential for research into bench gallows, but the most obvious investigations provide no answers.
It has long been observed that bench glyphs, [ch] and [sh], are less frequent at the start of first words in a line. Certainly Currier had made this observation back in the 1970s. A related, but less well-known feature is that words beginning with a bench glyph and sometimes more frequent in the second position of a line.
A couple of tables will help to illustrate the feature. The table below shows the number of words beginning [ch] in each position from the left by each hand/scribe.
Position from left
1
2
3
4
5
Hand 1
91
439
350
296
223
Hand 2
24
188
170
190
174
Hand 3
30
255
229
224
194
The table below shows the number of words beginning [sh] in each position from the left by each hand/scribe.
Position from left
1
2
3
4
5
Hand 1
96
213
142
142
103
Hand 2
36
222
175
131
114
Hand 3
47
217
110
95
90
The figures given are counts for three scribes/hands as identified by Lisa Fagin Davis (2020). The total number of words written by each hand differs, so the counts are not directly comparable. The interest is in how the numbers change from left to right.
Were words distributed randomly (or just evenly according to a principle which was “ignorant” of the line) then we would expect to see the numbers of these words to be broadly equal. The counts would decrease from left to right, simply because not all lines contain two, three, four, or five words.
Yet we see clearly two patterns as mentioned above:
In nearly all cases words beginning [ch] or [sh] in the leftmost position are significantly lower than subsequent positions. The only exception is for words beginning [sh] written by hand 1, where the fifth position is nearly as low as the first.
In some cases the number of bench-initial words in the second position is noticeably higher than subsequent positions. This is true for hand 1 in both cases, but also hands 2 (though weak) and 3 for [sh].
How can these features be explained? Is there some way we can even out the occurrence of bench initial words?
Several years ago we look at linestart words, which showed that the initial glyphs for words at the start of lines were quite different. Words beginning with [ych], [ysh], [dch], [dsh] were strongly tied to the start of lines. The possibility that words at the start of lines may have additional initial glyphs was explored in another post on the subject.
The hypothesis is thus that by removing [y] or [d] from certain words at the start of lines, we’ll end up with a more even distribution of words beginning with [ch] or [sh].
Below is a table showing the distribution of words beginning [ych]/[ysh] according to position in the line and by individual hand/scribe.
Position from left
1
2
3
4
5
Hand 1
75 / 14
4 / 0
0 / 0
1 / 1
1 / 0
Hand 2
23 / 21
3 / 0
0 / 0
3 / 1
3 / 2
Hand 3
68 / 34
2 / 1
1 / 0
2 / 0
0 / 0
And again, the same table as above but this time for [dch]/[dsh].
Position from left
1
2
3
4
5
Hand 1
61 / 27
7 / 3
12 / 4
8 / 3
20 / 0
Hand 2
35 / 40
3 / 0
0 / 0
1 / 4
0 / 2
Hand 3
36 / 29
3 / 1
1 / 0
2 / 1
2 / 0
The tables show that these words are strongly line initial, though [dch] in hand 1 appears to occur throughout the text in lower numbers.
If we take the hypothesis that all words beginning [ych], [ysh], [dch], [dsh] should have the initial [y] or [d] removed to yield a word beginning [ch] or [sh], doe that even up the distribution of bench initial words? The table below shows the changes to the distribution of bench initial words, with the original in normal text and the new in bold.
First for [ch]:
Position from left
1
2
3
4
5
Hand 1
91 / 227
439 / 450
350 / 362
296 / 305
223 / 244
Hand 2
24 / 82
188 / 194
170 / 170
190 / 194
174 / 177
Hand 3
30 / 134
255 / 260
229 / 231
224 / 228
194 / 196
And again for [sh]:
Position from left
1
2
3
4
5
Hand 1
96 / 137
213 / 216
142 / 146
142 / 146
103 / 103
Hand 2
36 / 97
222 / 222
175 / 175
131 / 136
114 / 118
Hand 3
47 / 110
217 / 219
110 / 110
95 / 96
90 / 90
The result show some improvement in the distribution of bench initial words, which is not a surprise given that the changes were designed with that in mind. However, the range of improvement differs across hands and between [ch] and [sh].
For [ch], none of the improved distributions match well. That of hand 1 is the most improved, and barely reaches the count in position 5. The others are still too far off. It may be that changes to Grove words,as discussed previously, could improve these scores further, but they may still fall short.
For [sh] the story is quite different. For both hand 1 and hand 3 the new distributions seems almost perfect, with position 1 matching positions 3, 4, and 5. (Of course, position 2 is still too high, which is another issue.) For hand 2 the new distributions isn’t nearly as good as must be considered almost as poor as for those beginning [ch].
The number of Grove words for each section is around 45 [pch], 8 [fch], 10 [psh], and 1 [fsh]. The number is difficult to calculate without looking at every example, because some may turn out to genuinely start with a gallows. Removing that gallows to obtain a word starting [ch] or [sh] would be a wrong move. Even so, they still wouldn’t create a good match for bench initial distribution.
The question of what causes the spike in bench initial words in position 2 must be left unanswered. There are several avenues to pursue, such as the preceding word and the glyphs which follow the initial bench in position 2 words.
(This post partly stems from a conversation some time ago with Marco Ponzi about the spike in bench initial words in position 2 of a line.)
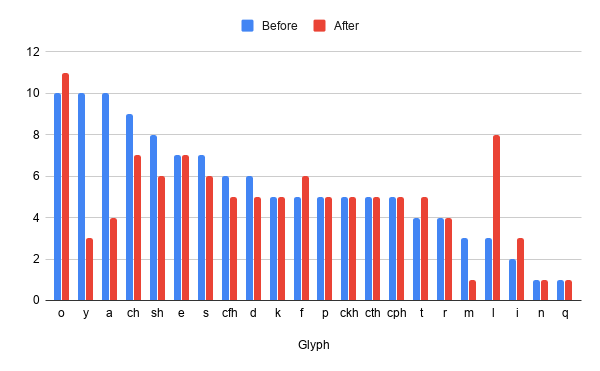
Each glyph in the Voynich script has a different distribution. Some occur in a particular position, such as the start, middle, or end of words, or adjacent to specific glyphs, such as [q] before [o]. Some glyphs may appear adjacent to many others, some only a few. We can think of glyphs as having a more or less diverse distribution based on how many glyphs they occur next to.
The distribution of glyphs in relation to other glyphs also differs according to the direction of that relationship. The glyphs which come before [ch] are not the same as those which come after it. There may be both a different set of glyphs and a different number of glyphs which come before and after.
The chart below shows the number of different glyphs which come before and after the 22 most common glyphs in the text. The number of glyphs is for each is counted up to at least 95%+ of its distribution, so rare adjacent glyphs are not included. Also, I have taken [ch, sh, ckh, cth, cfh, cph] to each be single glyphs, and also counted a word break (or space) as a glyph to indicate the position at the start or end of a word.
Eighteen of the 22 glyphs have either the same or nearly the same level of diversity before and after. The highest is [o] which can take any of 10 glyphs before and 11 glyphs after. The lowest are [n] and [q] which both take one before and one after.
Four for of the 22 glyphs in the above chart should be looked at in more detail.
[y] and [a]
The glyphs [y] and [a] both show a distribution with significantly lower diversity of glyphs after them than before. Although they show significant overlap in the glyphs which come before, they have no overlap in the glyphs which come after.
Although the difference in the diversity of glyphs before and after [m] is small in number it is relatively big. The glyph [m] has three different glyphs which can come before, but only one after (in fact, not a glyph, but a space.)
The strict word-final position of [m] is probably mostly to blame. Though [q] and [n], which are strongly tied to the start and end of words respectively, have the same number of glyphs appearing on both sides. It could be that, as suggested by a number of researchers, [m] is a word-final variant of another glyph.
[l]
The most interesting result from measuring the diversity of adjacent glyphs is that [l] is totally different from every other glyph. While only three glyphs come before [l] there are eight glyphs which can come after. It is the second most diverse glyph with regard to what glyphs can follow it.
This result is reminiscent of those from first-last combinations where [l] didn’t fit well into the proposed division between ‘strong’ and ‘weak’ glyphs. There is clearly something about the way [l] interacts with other glyphs which makes it unlike others.
The reason for this difference is unknown and deserves further investigation. I’ll likely follow up this post with a more in-depth look at [l], including breaking down its distribution into Currier A and B.
The text of the Voynich manuscript exhibits relationships between neighboring words that have not formally been explored. The last and first glyphs of adjacent words show some dependency, and certain glyph combinations are more or less likely to occur. The patterns of preferences for glyph combinations demonstrate the existence of higher-level glyph groups. The behavior of the glyph combinations may arise due to changes in a glyph caused by its neighbor.
In my recent post about the new word structure I’ve called Body Rank Order I said that the rule for rank order wasn’t settled and may need further refinement. The rank order should either increase or stay constant from left to right, but I felt that “stay constant” was wrong and not elegant enough as a model. I noted that only a minority of words needed the “stay constant” part of the rule to be correct, and some of those words were unusual in other ways.
A good portion of the “stay constant” words are unusual because they occur mostly in the linestart position. Words starting [ych] and [ysh] are the two types which I wish to discuss in this post as they show the relevant patterns most strongly.
In the Body Rank Order model words beginning [ych] and [ysh] would be split into syllables in this way: [y] would be the first syllable body in the word with the next syllable starting [ch] or [sh]. Thus [ycheey] is composed of the syllable bodies [y] and [cheey] while [yshey] is composed of the syllable bodies [y] and [shey]. Some words, such as [ycheol], have a coda on the second syllable or, as with [yshedy], have three syllables.
The key point is that both [y] and any syllable starting with a bench [ch, sh] are in rank 1. Thus all words beginning [ych] or [ysh] have a body rank order which stays constant. There are 16 such words with four or more tokens in the Voynich text, and they total 182 tokens, or 35% of all “stay constant” exceptions to the model.
We know that both [y] and syllables starting with a bench [ch, sh] must be in rank 1 as they often occur before rank 2 syllables, such as those starting [k, t]. Neither can be placed into a different rank without causing greater exceptions.
The linestart phenomenon, where the first glyphs of words found at the linestart differ statistically from those in the rest of the text, adds to the problem. About 80% of words beginning [ych] and 90% of those starting [ysh] occur at the start of lines. Thus they are neither normal in their structure nor their distribution.
The solution comes from resolving both problems at once. Were [y] removed then the words would be both structurally normal and statistically normal in their distribution. Indeed, according to Transformation Theory this is the likely scenario: all words beginning [ych, ysh] originally began [ch, sh], and some unknown process added [y] to the start of some words beginning [ch, sh] which were at the start of a line.
It must be borne in mind that not all words beginning [ych, ysh] occur at the start of lines, nor that words beginning [ch, sh] are not found at the linestart. Simply that the environment for adding [y] was more prevalent in the linestart position, though could be absent and could be found elsewhere.
They key conclusion, however, is that the text of the Voynich manuscript must be “normalized” by removing the [y] from the start of words beginning [ych, ysh].
(It may be that other “normalization” is needed elsewhere, and that the difference between the “transformed” text and the “normal” text is hindering decipherment efforts.)
The New Word Structure I published last week relies heavily on older research, specifically the idea that [y] and [o] are equivalent, and that [y] can be deleted in some environments. Indeed, since formulating these ideas most of my text research has relied on them, either openly or implicitly. Much of what I believe about the text would become invalid, or at least seriously undermined, were these ideas to be proven wrong.
The worry I have is that the separate ideas have been pieced together and extended over time (for example, [y] deletion after [ch, sh] as well as [e]) despite being used for a single goal. The goal is to show that [y] and it various forms and expressions are a match for [o], and therefore that [o] and [y] are in the same “class” of glyph.
Although we expect all glyphs to have different frequencies in detail, certain glyphs, such as [ch, sh] or [k,t], share the same distributions. That is, even though they occur more or less in some positions, they appear to be valid in the same positions. My expectation is that [y] is valid in the same positions as [o] once all its forms have been included, but I don’t believe I have ever properly tested this.
Mapping and Matching
To test if the distribution of [y] matches that of [o] I first made table of possible trigrams containing [o] and their token counts. Each trigram consisted of [o] with one of the common 22 glyphs or space before and after it. This gave 529 combinations, ranging from the unlikely [noq] (0 tokens) to the very common [.ok] (2481 tokens). (The full stop/period here denotes a space or word break.)
The reason for the trigram is that various expressions of [y] depend on the glyphs which come before or after. So [a] depends on the following glyph while a null expression/deletion relies on the preceding glyph.
The trigram table shows the actual environments in which [o] occurs and where it does not. The expressions and forms of [y] can then be mapped to the table, slowly building up the coverage and showing us if it doesn’t match any key parts of the distribution of [o].
After [q] ~ 21% of occurrences
We can start with the approximately 21% of [o] occurrences which definitely can’t be matched by [y]. Nothing can replace [o] after [q] and it’s universally acknowledged that this this particular bigram (and all the trigrams which contain it) is its own thing. Some would go as far to say that [qo] is a digraph.
I feel there’s evidence that [q] is specifically added to words starting [o]. This would make this particular distribution more about how [q] works rather than [o]. It is enough to say that nobody expects [o] to be replaced by another glyph in this environment so we don’t have to worry about it.
Before [r, l, i, n, m] ~ 34%
The glyphs [r, l, i, n, m] are important as they have been identified as the main glyphs which [a] occurs before. Thus for all the occurrences [o] in this environment we would expect them to be replaced not by [y] but [a].
If we look at some of the most commons trigrams for [o] before these five glyphs we can see that [a] validly replaces [o] in all cases.
With [o]
Tokens
With [a]
Tokens
[chor]
527
[char]
159
[chol]
804
[chal]
124
[eor]
465
[ear]
171
[eol]
1009
[eal]
140
[kor]
171
[kar]
572
[kol]
289
[kal]
631
[tor]
157
[tar]
378
[tol]
334
[tal]
391
[dor]
160
[dar]
814
[dol]
223
[dal]
756
[lor]
167
[lar]
87
[lol]
166
[lal]
90
[doi]
45
[dai]
2170
[chon]
4
[chan]
14
[chom]
29
[cham]
40
[eom]
35
[eam]
29
[lom]
25
[lam]
43
We can clearly see how the differences in frequency changes across the trigrams. The trigrams with [a] and sometimes more, and sometimes less, common than those with [o]. But in all cases they are no less valid, which is an excellent sign.
(I invite the reader to stop and this point and try to replace [o] with any other glyph and get results as half as good.)
At the end of a word ~ 5%
At the end of a word [o] should always be replaced by [y]. The glyph [a] barely occurs in this position due to the lack of a conditioning environment.
The most common trigrams at the end of a word are shown below with their matches containing [y].
With [o]
Tokens
With [y]
Tokens
[cho.]
183
[chy.]
959
[sho.]
184
[shy.]
270
[eo.]
436
[ey.]
3967
[do.]
37
[dy.]
6718
[ro.]
38
[ry.]
283
[lo.]
49
[ly.]
512
The glyph [y] is clearly much more common in the final position than [o]. We might have expected the large token count for [dy.] given its prevalence as a word ending. Yet [ey.] is clearly much more common also. It’s not a problem for our purposes, however, as we’ve shown that [y] can validly replace [o] in all these position. Indeed, the greater issue that some of the token counts for [o] that they barely feel valid.
At the start of words before glyphs which don’t cause [a] ~ 25%
The start of a word is the other place where we would expect to see [y] replace [o]. We’ve already looked at [o] before [r, l, i, n, m] and we take that as including occurrences at the start of words. But [o] is also common before a few others glyphs in this position, as seen in the table below.
With [o]
Tokens
With [y]
Tokens
[.oa]
79
[.ya]
15
[.och]
73
[.ych]
241
[.oe]
132
[.ye]
9
[.ok]
2481
[.yk]
631
[.ot]
2427
[.yt]
529
[.od]
245
[.yd]
63
[.os]
61
[.ys]
12
We’ve clearly run into a problem here. The trigrams [.ya, .ye, .ys] have far too low token counts to be valid. We might be able to forgive [.ya], as the two glyphs are technically two forms of [y], but the other trigrams are still wrong.
In neither case does there appear to be a solution. The trigrams [.ae, .as] are not only outside the expected rules for [a], but they’re also less common still. The trigrams together account for about 1% of [o]’s distribution: a small amount but still a gap.
In the middle of words after [e] but not before [r, l, i, n, m] ~ 6%
I think that this is the first really difficult part of my ideas for some to understand. We know that [y] is relatively uncommon in the middle of words, and yet [a] only occurs before some glyphs. What is the form of [y] used before other glyphs?
The answer I came up with is that [y] is deleted, or simply not expressed, when it should follow [e]. So if we imagine [okeody] to be made from the words [okeo] and [dy], they [okedy] is made from the words [okey] and [dy]: neither [okeydy] nor [okeady] exist.
The four most common trigrams demonstrate the match well, with “null” simply meaning that [y] is not expressed.
With [o]
Token
With null
Tokens
[eok]
116
[ek]
491
[eot]
54
[et]
214
[eod]
926
[ed]
5004
[eos]
235
[es]
428
Again, there are a few rarer trigrams with [e] which don’t work so well. The two most common are [eoy, eoa], which I wouldn’t expect to be common anyway due to the double [y].
In the middle of words after [h] but not before [r, l, i, n, m] ~ 6%
This environment is an extension of the one immediately above. There are many places where trigrams such as [chok] and [chod] and no equivalent with [y] or [a]. So I extended the argument used for [e] to cover benches as well.
Interestingly, this extension predated the discovery that benches help determine the length of [e] sequences. The outcome of that discovery is the hypothesis that benches could contain a “captured” [e], meaning that the environment following a bench is the same as following [e]. The use of [h] is to highlight the fact that the same is possibly true of bench gallows.
Below are some common examples.
With [o]
Tokens
With null
Tokens
[chok]
244
[chk]
160
[chot]
179
[cht]
84
[shok]
64
[shk]
54
[shot]
35
[sht]
19
[chod]
361
[chd]
815
[chos]
83
[chs]
108
[shod]
144
[shd]
181
[shos]
19
[shs]
23
[ckhod]
16
[ckhd]
36
[cthod]
49
[cthd]
30
Despite this environment being an extension of the argument for [o] after [e], it works perfectly well. The same issue arises with trigrams with [y] and [a], which is once again expected.
Everything else ~ 4%
This is the nub of the problem outlined at the start: my attempt to match [y] with [o] has not been systematic. I’ve been unsure of how well [y], [a], and null cover the whole of [o]. This 4% represents everything I’ve overlooked and it needs to be addressed.
To start with, about 0.5% of “everything else” is composed of really rare trigrams. The trigram [doa] has 8 occurrences. It might not be at all normal for [o] and I shan’t try to explain how [y] covers it.
However, some trigrams are common enough that they deserve addressing. Below are the nine most common, all with twenty tokens or more. I’ve added columns for their matches with [y], [a], and null, just so we can see if any of the existing explanations work.
With [o]
Tokens
With [y]
Tokens
With [a]
Tokens
Null
Tokens
[tok]
23
[tyk]
4
[tak]
4
[tk]
1
[kod]
88
[kyd]
18
[kad]
8
[kd]
11
[tod]
112
[tyd]
23
[tad]
4
[td]
20
[dod]
24
[dyd]
22
[dad]
9
[dd]
23
[sod]
32
[syd]
4
[sad]
1
[sd]
32
[sos]
20
[sys]
0
[sas]
4
[ss]
6
[rod]
68
[ryd]
4
[rad]
4
[rd]
43
[lod]
51
[lyd]
4
[lad]
1
[ld]
452
[los]
21
[lys]
3
[las]
4
[ls]
162
Well, this is a bit of a mixed bag! It’s clear that there is no single pattern. That’s okay, as this is basically a residue category for [o]. There’s nothing particular which brought all these trigrams together other than the fact that they weren’t already mapped to another form of [y].
We’ll have to take these trigrams as groups according to what looks like the best answer.
[tok] and [sos]: There doesn’t seem to be a great answer for these two. Neither are very common themselves, but all the possible matches are poor. While [tok] isn’t a huge problem as it’s quite unusual in itself (two gallows in a single word) the trigram [sos] seems more normal and should have a similar solution to [sod] or [los].
[kod], [tod], and [dod]: These three seem as though two or even three of the possibilities might exist. Why is that? Could it be that the writer didn’t know what to do with [y] in these environments?
[sod], [rod], [lod], and [los]: All these clearly prefer the “null” version. This is a very interesting result as the deletion of [y] was built upon the idea that [e] (or a “captured” [e]) might somehow stand in for the missing [y]).
Yet there is something more worth noting. Three of the trigrams with [o], [sod], [rod], and [lod], are more common than expected in words at the start or end of line. Similarly, [sd], [rd], [ld], and [ls], are also more than than expected in words in these positions.
This could be a sign that, at least for these four trigrams, the match between the [o] and null versions is the right one.
Afterword
I’m still not convinced that I have my idea about [y] matching [o] completely nailed down. There seems more that needs to be said, or something which I’m missing. Yet the majority of the distribution of [o] does seems to be covered within existing arguments.
Even if in a few places, such as with [.oe] and [.es], it does seems to fail, and the residue is quite confusing, there’s still much more good about the idea than bad. Maybe there is something which will tie all the pieces, including the gaps, into a whole. There needs to be an underlying reason why [y] becomes [a] in some places or is simply not expressed in others.
I definitely haven’t found that reason yet, but I’m willing to stand by my hypothesis while I look for it.
A few years ago I published a couple of posts regarding the low level and high level structure of Voynich words. While I think I got a number of things right I have had to revise the low level structure since that post, and now it’s time to revise the word structure completely. I believe there is a much simpler way to express how Voynich words are structured than before.
Before I start I want to mention the work of Jorge Stolfi, specifically his Grammar for Voynichese Words and Prefix-Midfix-Suffix Decomposition of Voynichese Words. Although my work is not directly built upon his the reader will notice some similarity. I want to acknowledge that I’ve found his work an inspiration from the very earliest day of reading about the manuscript.
The main difference between Stolfi’s work and my own is the unit of analysis. Stolfi analysed the structure of words according to categories of glyphs. I have based my analysis on “syllables” – regular divisions of words according to some basic rules. I will first need to explain a little bit about syllables and how my the process of division works.
What is a Syllable?
Although most readers will know what a syllable is, it’s useful to explain a couple of terms that I will use. You can think of a syllable as a string or bundle of sounds uttered close together: a vowel (or vowel-like sound) and optional consonants pronounced before or after it. When speaking about the components of a syllable the vowel is called the nucleus, the consonants before it the onset, and the consonants after it the coda.
Here’s a simple diagram from Wikipedia (where the sigma sign stands for ‘syllable’):
The components can be grouped in different ways. So the nucleus and coda together are called the rhyme, while the onset and nucleus can be called the body. For our purposes the model of body + coda will be the most relevan.
Finding Syllables
The basis for dividing words into syllables is the identification of [o] and [y] as key glyphs. They occur very commonly in most words and mostly in the same positions as each other. We can consider them as being the nucleuses of our syllables, whether or not we wish to consider them as vowels.
(While it is not necessary to believe in the equivalence of [y] and [a] or in [y] deletion to follow this word structure, I have written it from the perspective of those two hypotheses being true. For every mention of [y] it must be understood to represent [y], [a], and those locations where [y] is missing such as after [e] sequences or benches [ch, sh].)
We divide up a word by first finding all the occurrences of [o] and [y]. There are as many syllables as occurrences of these glyphs. Each syllable consists of the [o] or [y], all the glyphs before it until another [o] or [y] or start of the word is reached, and all the glyphs after if it is the final [o] or [y] in the word.
Let us take an example: [qokedar] (8 tokens). First we restore the missing [y] after [e] and change [a] to [y], giving: [qokeydyr]. Then we apply the syllable division process outlined above: there are three occurrences of [o] and [y] in the word, giving the syllables [qo] + [key] + [dyr].
It should be noted that [qo] and [key] as syllables as bodies only and only [dyr] has a coda. Indeed, the process of syllable-finding makes it impossible for there to be a coda except at the end of words, as glyphs are always assigned to a following syllable where possible.
This problem can arise with other languages, and knowing whether a consonant belongs to the coda of one syllable or the onset of the other is sometimes a difficult judgement. Phonotactic rules can be helpful to resolve the issue. If we think of the word carpet we know it has two syllables, yet we also know that syllables don’t start /rp/ so the second syllable might be /et/ or /pet/, but definitely not /rpet/.
Though we don’t know the phonotactic rules for the Voynich text we can use a similar judgement to check if the syllables we find are valid. A word such as [choldy] (10 tokens) looks more like [chol] + [dy] than [cho] + [ldy], though the syllable-finding process would give the latter. However, we can find a few words starting [ld], showing that syllables can start with this cluster (indeed, [ldy] is the most common with 25 tokens).
Only in a handful of cases do we feel the need to say that a non-final syllable has a coda, and most of those concern [i], [n], [m] not being at or near the end of a word. Thus we can consider the placement of codas at the end of words not to be an issue. Final syllables with codas will be considered along with other syllables as bodies (onset and nucleus) separate from their codas. Codas will be addressed toward the end of this post.
Permissible Bodies
For the purposes of this structural analysis I took all words with four or more tokens (1109 types) and divided them into syllables by hand. The number of syllables in each word type ranged from 1 to 4, though a few words could not be split into syllables. The table below gives the number of different word types by syllable length:
Number of Syllables
Word Types
%age
0 syllables
29
2.6%
1 syllable
326
29.4%
2 syllables
614
55.4%
3 syllables
136
12.3%
4 syllables
4
0.4%
We can see straight away that not only can be majority of words be split into syllables with this process, but that the number of syllables falls into a narrow range of 1 – 3 syllables.
Moreover, the division of Voynich words into syllables gives us a structurally coherent set of syllable bodies. This is partly due to the way the process works, such as inserting missing [y], but the structure of syllables is relatively simple. The number is also relatively small. Only 135 different syllable bodies were found in the words I analysed, and I would not expect an analysis of all words to expand this significantly.
Below is a list of the twenty most common bodies and the number of word types they occur in:
Syllable Body
Word Types
dy
265
o
254
qo
144
y
138
ky
68
cho
56
ty
53
chy
51
ry
39
chey
37
ly
35
to
28
key
27
ko
25
shey
24
keo
23
sho
23
cheo
21
keey
21
lky
19
Body RankOrder
Up to now most of the things in this post have been previously discussed. What follows is a new theory which describes the structure of Voynich words. It is based on syllable bodies being ordered within words in predefined ways.
We saw above that 97% of words in the Voynich text have 1 – 3 syllables. Therefore we can say that there are up to three “slots” into which syllable bodies fit within words. Some syllable bodies, such as [qo, o, dy], are highly positional. We can guess beforehand which slot these bodies are likely to occur in for any given word.
In fact, every syllable body has a value which determines its position within a word. The slots must be filled in a particular order for the word to be valid. I call this theory “Body Rank Order” and it has a simple set of rules:
Each syllable body has a Rank of 1, 2, or 3.
Each word has a number of slots equal to its number of syllables.
From left to right the Rank of each syllable body must increase (or stay constant).
The ranks for all syllable bodies which occurs in five or more word types are as below:
tcheo, tchey, tcho, tchy, teeo, teey, teo, tey, to, ty
dy
ldy
ly
ry
Not all of combinations of bodies from ranks 1, 2, and 3 occur and this table should not be taken as a guide to simply construct words. It may also be that one or two of these syllable bodies might belong better in a different rank dependent on future research ([so] is the most likely to need moving). Yet we can clearly see that the ranks are quite coherent: all syllable bodies starting with a bench [ch, sh] are in Rank 1, and all syllables with a gallows are in Rank 2.
The Body Rank Order fits Voynich words well, with no issues for the 350 most common words. The most common word which breaks the rules is [qokechy] with 13 tokens, having a rank order of 121. The next is [dalor] with 8 tokens, having a rank order of 32.
Of course, every one syllable word fits the theory perfectly, but the statistics for words with two or more syllables is still good:
Syllables
Types
Disordered
%age
2
614
6
1%
3
136
5
4%
4
4
4
100%
All four syllable words are “disordered”, but they’re so rare that it is hardly an issue for the theory. It seems that four syllable words are unusual in multiple ways.
For two and three syllable words, the problems are caused by just a few errors:
[chy] and [y] coming at the end of a word rather than the start.
[lo] being out of order.
A coda coming in the middle of a word.
This last error hasn’t really been mentioned but can be summarised. We can assign the rank of 4 to a coda as it almost always comes at the end of a word. Where it occurs in the middle of a word an error is thus found. The two word types in question are [daiidy] (6 tokens) and [dairal] (4 tokens).
Conclusion and Next Steps
Taking into account words which couldn’t be syllabified (2.6%), words with more than three syllables (0.4%) and words with rank errors (1%) we can see that the Body Rank Order theory accounts for 96% of all word types with more than four tokens.
The theory is thus highly successful yet still very simple. It builds on previous research concerning [y] while presenting a new field for further research. It reveals a word structure which demands further investigation.
The theory could be further refined, mentioned above with regards to [so]. This body is different as it mostly occurs at the start of lines, where different rules seem to apply, and a few others are likely the same.
It might be worth also calculating the rank orders for all word types, no matter how many tokens, to discover how well it describes unusual words. It is likely that unusual words are unusual for a reason, as with four syllable words.
Lastly, I stated above that the rank order within words should increase form left to right, or stay constant. I found that the most common words always showed an increase from left to right. The most common word which didn’t show an increase, but stayed constant, was [daly] (27 tokens).
The percentage of words for each syllable which didn’t show an increase was always a relatively small portion: 8% for two syllable words, and 5% for three syllable words. This would mean that for both 91% of words showed an always increasing rank order, rather than an error or staying constant. It may be that with further refining of the model this number can be brought down, thus simplifying and strengthening the theory.